使用缓存
读写分离
分库分表
消息队列
系统中难免会出现一些比较慢的查询,这些查询要么是数据量大,要么是查询复杂(关联的表多或者是计算复杂),使得查询会长时间占用连接。
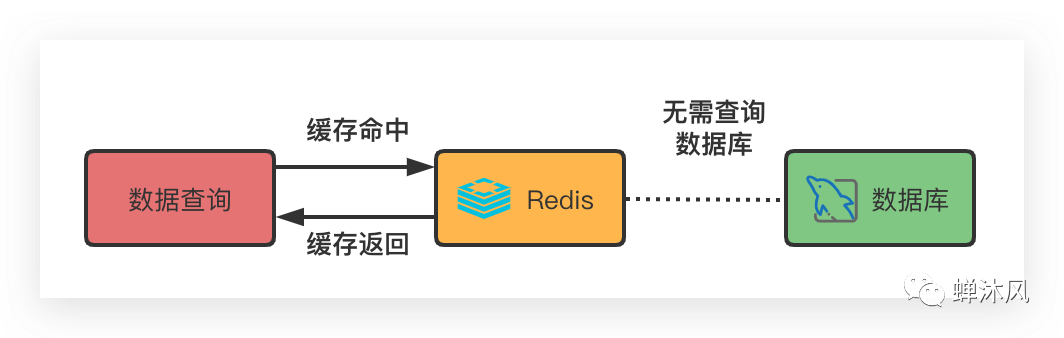
如果这种数据的实效性不是特别强(不是每时每刻都会变化,例如每日报表),我们可以把此类数据放入缓存系统中,在数据的缓存有效期内,直接从缓存系统中获取数据,这样就可以减轻数据库的压力并提升查询效率。
缓存的使用
项目的初期,数据库通常都是运行在一台服务器上的,用户的所有读写请求会直接作用到这台数据库服务器,单台服务器承担的并发量毕竟是有限的。
针对这个问题,我们可以同时使用多台数据库服务器,将其中一台设置为为小组长,称之为master节点,其余节点作为组员,叫做slave。用户写数据只往master节点写,而读的请求分摊到各个slave节点上。这个方案叫做读写分离。给组长加上组员组成的小团体起个名字,叫集群。

这就是集群
注:很多开发者不满master-slave这种具有侵犯性的词汇(因为他们认为会联想到种族歧视、黑人奴隶等),所以发起了一项更名运动。
受此影响MySQL也会逐渐停用master、slave等术语,转而用source和replica替代,大家碰到的时候明白即可。