原文来自《v3.0-JavaGuide面试突击版》
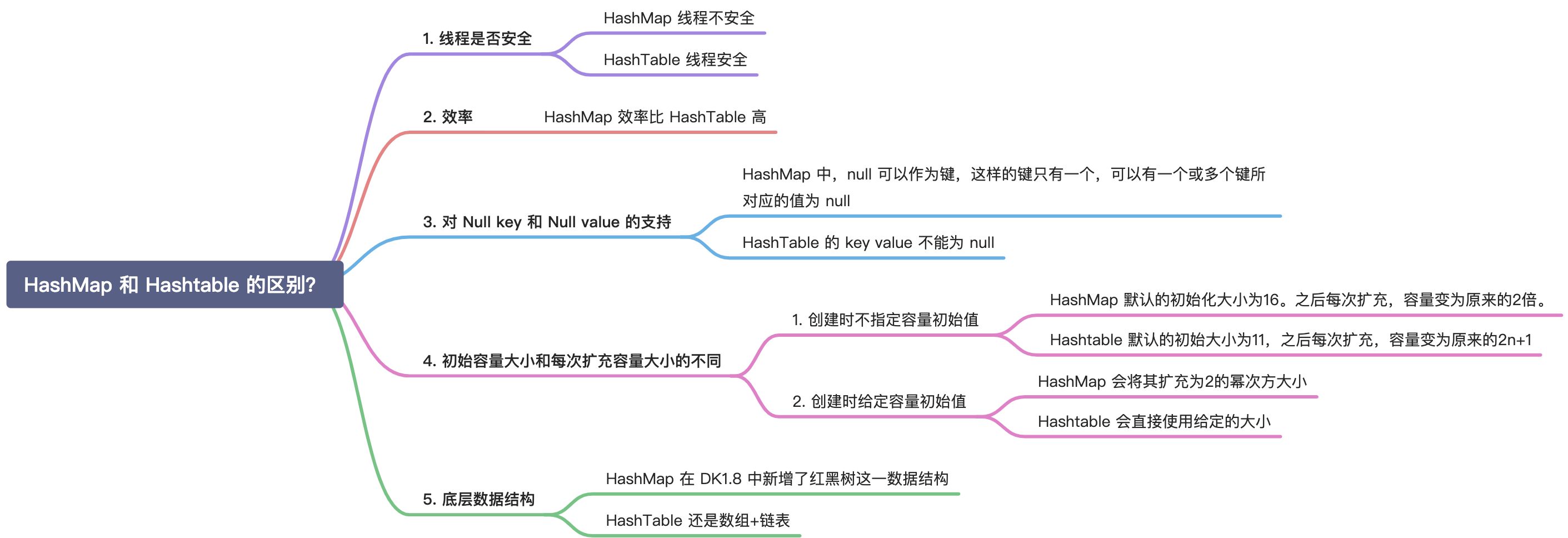
① 创建时如果不指定容量初始值,Hashtable 默认的初始⼤⼩为11,之后每次扩充,容量变为原来的2n+1。HashMap 默认的初始化⼤⼩为16。之后每次扩充,容量变为原来的2倍。
② 创建时如果给定了容量初始值,那么 Hashtable 会直接使⽤你给定的⼤⼩,⽽ HashMap 会将其扩充为2的幂次⽅⼤⼩(HashMap 中的 tableSizeFor() ⽅法保证,下⾯给出了源代码)。也就是说 HashMap 总是使⽤2的幂作为哈希表的⼤⼩,后⾯会介绍到为什么是2的幂次⽅。
HashMap 中带有初始容量的构造函数:
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
下⾯这个⽅法保证了 HashMap 总是使⽤2的幂作为哈希表的⼤⼩。
/**
* Returns a power of two size for the given target capacity.
* 对于给定的目标容量,返回2的幂次方大小。
*/
static final int tableSizeFor(int cap) {
int n = cap - 1; n |= n j>k 1;
n |= n j>>>k 2;
n |= n j>>>k 4;
n |= n j>>>k 8;
n |= n j>>>k 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
HashMap从源码分析:
HashMap在 put 的时候会调用 hash() 方法来计算 key 的 hashcode 值,可以从 hash 算法中看出当 key==null 时返回的值为0。因此key为null时,hash 算法返回值为0,不会调用key的hashcode方法。